I was just uploading some stuff, and so this isn’t the best example, but it might be a good starting point to explain the problem.
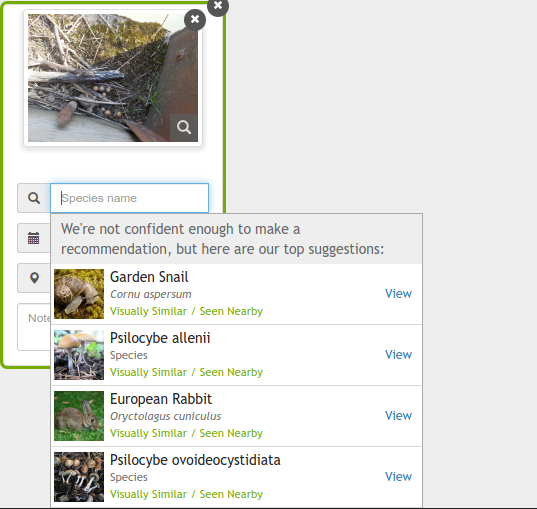
To be fair, this is obviously an unusual observation: my intended observation was the wasp galls, which are out of their element. But the AI picked some curious options…snails, rabbits, or several types of psychedelic mushrooms. Maybe the AI is thinking of opening a very experimental French psychedelic fusion restaurant?
Actually, let me clarify in case that sounded harsh or sarcastic: with lots of normal observations, it is still as good as it ever was. With common flowers from normal angles, it guesses them. But when it is something like this, or perhaps a bird in flight, it throws up a number of guesses seemingly without connection.