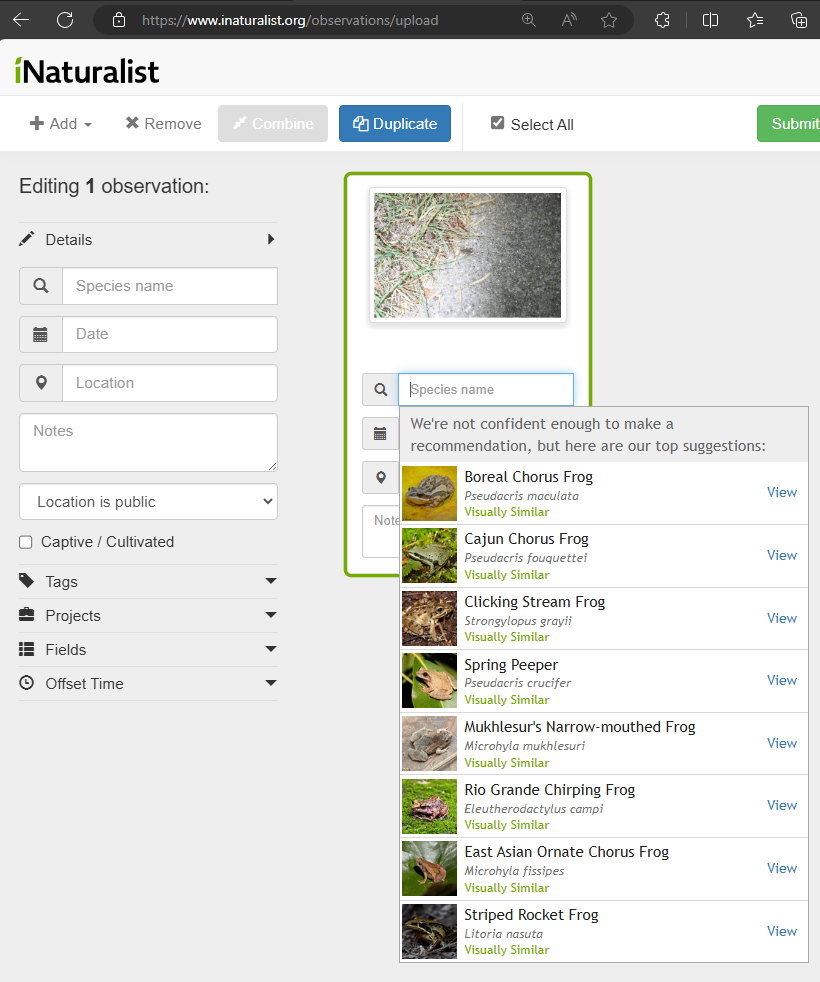
find an existing observation where the top suggestion is higher than species level. do you ever see one less than 5 dots?
try looking at the suggestions with nearby only turned on. the species-level suggestions might occasionally rise above 1 dot, but generally, they should be 1 dot (until the underlying scoring issue is fixed).
there are slightly different computer vision processes evaluating the photo on upload, after upload with no existing identification, and after upload with an existing identification. (and there are also variations when you use the expected nearby filtering with and without location and date.)
if you start an upload with the photo from that observation, you’ll see that the top suggestions are still frogs, as noted by willampaulwhite17 back in the day:
When you run an image through the “add observations” widget, there are basically two classes of results. Either “We’re not confident enough to make a recommendation, but here are our top suggestions:” or “We’re pretty sure it’s…” The computer vision model sitting behind this is calculating a confidence value for the top matching taxa based on the submitted image. My guess is that the switch between these two result categories (not confident / pretty sure) is based on a critical value of the confidence value, maybe 80% or 90%. Is this correct, and if so can we find out what this critical value is?
And then we would be having discussions here about what percent certainty is okay to agree with. And pushback that no amount of CV certainty is an acceptable replacement for human certainty. Which doesn’t seem like any better a situation than exists now.
For those who haven’t seen it yet, the new iNat Next app shows how sure the Computer Vision suggestions are on a scale from 1-5, and it can also offer suggestions for each photo in an observation individually: