Alex did leave iNat earlier this month, and his impact on iNaturalist has been huge. We’re all incredibly grateful for his contributions, both in engineering and just as a human and teammate, and I’m looking forward to hanging out with him in the future and seeing what he’s up to next.
Regarding contacting engineers: engineering is a team endeavor, and the engineers are going to continue the work as a team as they always have. Alex was a huge part of computer vision and the geomodel on iNat, but it’s also been a team effort with contributions from multiple engineers. As the iNaturalist team as a whole has evolved, we’re working on more clearly defining roles, and the engineering team will focus on engineering rather than interfacing directly with the community in threads like this. We have an engagement team at iNat who focus more on outreach and community engagement, and we’ll be the points of contact between engineering and the community. On the forum that’s primarily going to be myself, @carrieseltzer, and @seastarya. We can relay concerns and feedback to product and engineering. That’s a lot of what I’ve been doing for nearly all bug reports and feature requests for the past 7+ years.
We just released the latest Computer Vision/Geomodel update and have decided to revert back to the GRID approach that was used previously instead of the SINR approach that we went with for the last few models, based on feedback and reports from the community (thank you!). You can read more in the latest blog post.
From what I’ve seen in the threads you referenced, there would be no need to bother putting “in this region.” The complaints about this come from everywhere.
As you referenced fungi, I’ll revise that: people don’t like their obs being pushed back to Order.
Part of the problem is that many of those species did exist here until the most recent revisions. This is an inherent problem with the thread’s premise of “in regions with…” Given current taxonomic trends, that’s going to be every region, at least for certain taxa.
Macrolepiota procera and Macrolepiota prominens were the commonly applied Macrolepiota species in eastern NA before sequencing showed them to be not present and the proper species were described.
Those I at least understand.
M. zeyheri is a South African species, and M. clelandii is Australian, and I’ve never seen any indication that they’ve ever been commonly applied here. I pulled out Mushrooms Demystified, which was published originally in 1979, and the only Macrolepiota species even mentioned is procera (well, and rhacodes, but that’s now in chlorophyllum.)
All that is to say, I’m fighting the computer vision on species that no expert ever thought was present in eastern NA.
Also if something needs pushed back to order, it needs pushed back to order. I don’t see why that’s a problem. I’ve never seen why that is a problem.
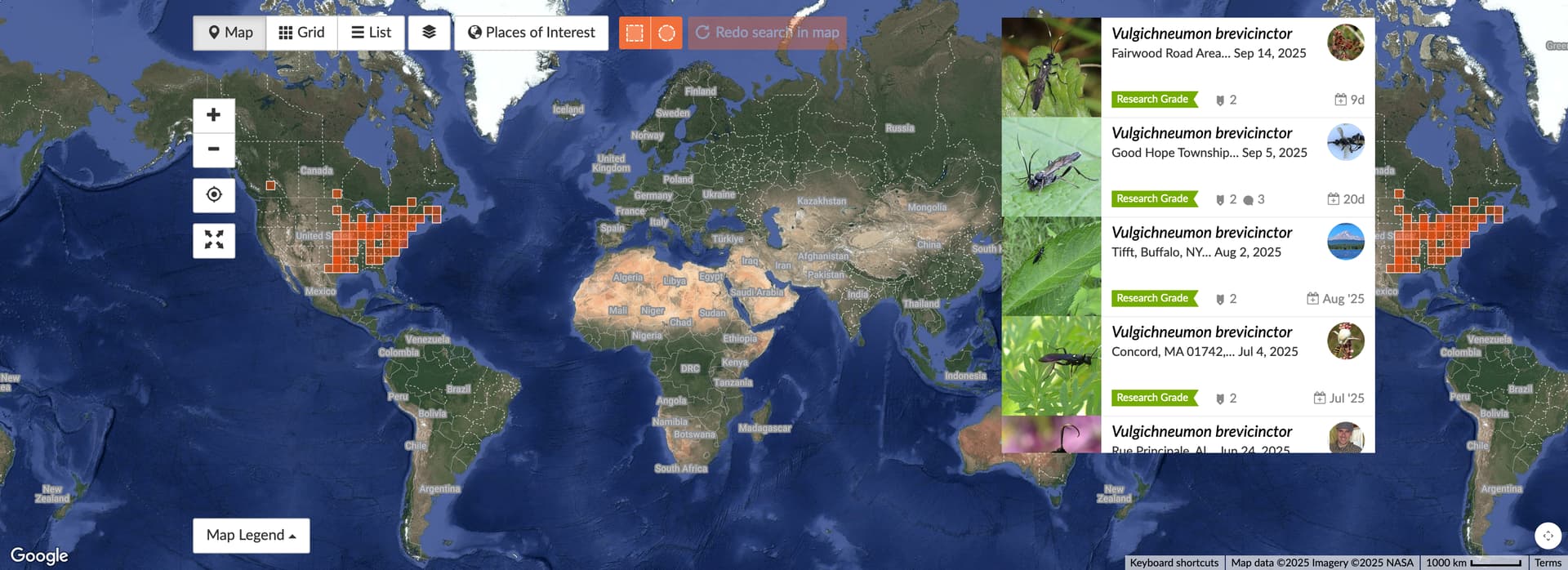
Thanks for the update, Tony. To me, a priority should be to understand why the geomodel for some species is covering such a vast area without confirmed observations. For example, the map of Research Grade observation for this wasp looks like this:
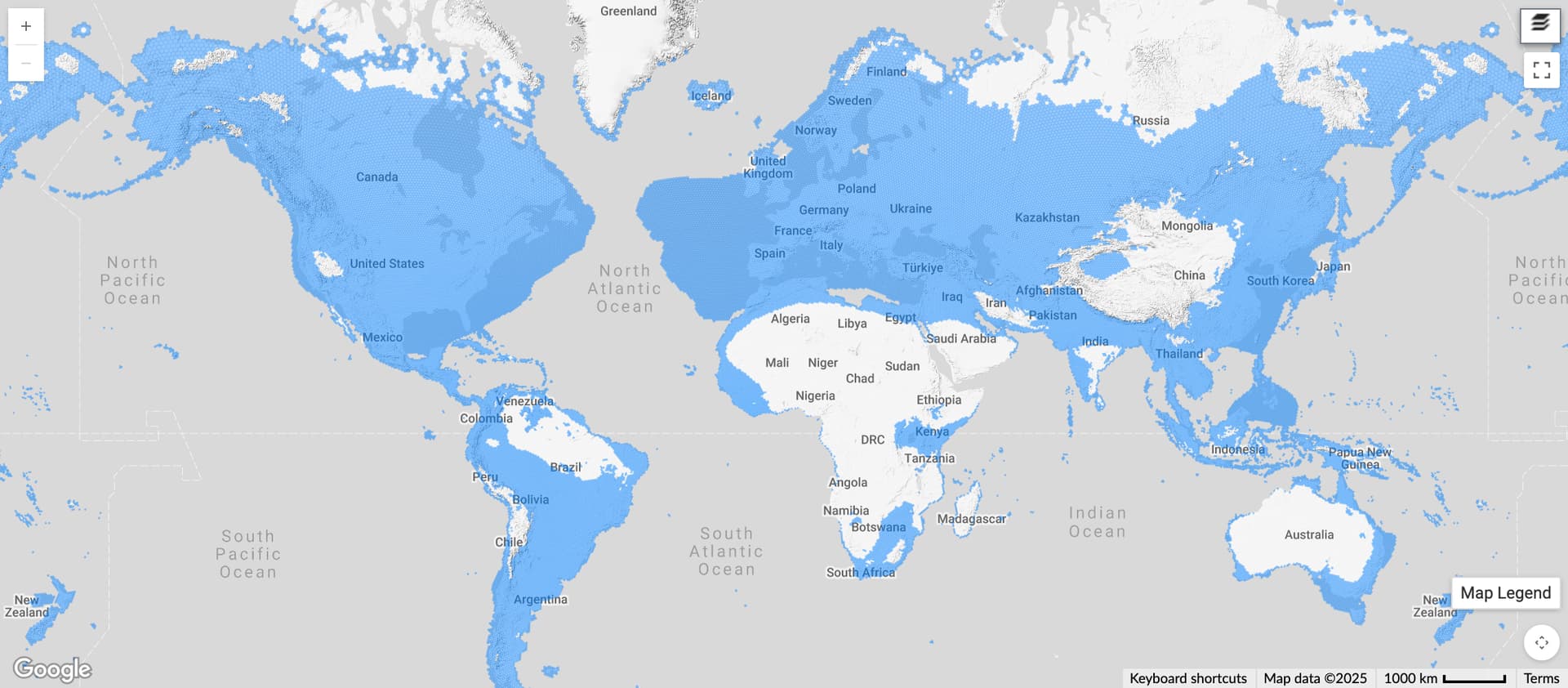
It only has Research Grade observations in North America, yet its new geomodel looks like this:
Even leaving aside the large areas of ocean included, there needs to some mechanism to get the model to back off in areas outside of the known distribution, either by masking the geomodel to within some buffer of Research Grade observations, or being more conservative about offering genus or family-level suggestions.
For building the geomodels, it might be useful to discard some small percentage even of the Research Grade observations which are outliers in terms of geography or other variables, to produce more conservative models. [In this case, there might have been a very small number, two or three, of non-North-American RG observations when the model training set was pulled]
Such behavior would also be helpful with certain species that have a tendency to show up as package or produce stowaways (or other sorts of human-aided transport), but fail to establish a population because the climate just isn’t right for them.
Yes. As a Lycorma delicatula researcher I feel that the CV should back off on specificity in IDs for almost all species. We really need research-grade observations for every single successful and failed jump dispersal to get comprehensive reporting, but in this day and age we have enough(?) people to identify new jump dispersals of all kinds of species except when they resemble species similar to those in the same geographical area. I just hope people don’t use a revised CVM to misidentify very rare hitchhikers.
This would be a very bad idea for hardier hitchhiking invasive species that make new establishments easily because oftentimes iNaturalist is the first step in people reporting an invasive species they accidentally transported. I and others in invasion biology also need RG observations of certain jump dispersals to remain RG, only if they are correctly identified, to have enough data points to support that their invasion of interest is a problem. We should make special exemptions for invasives that spread very fast and have high tolerances.
This is a very salient point. I think it likely a majority of known biological species cannot be identified as such from habit/habitus imagery. (Overall visual appearance in plants, fungi = habit, in animals = habitus.) By definition, biological species are based on reproductive isolation, and there is no rule of nature that reproductive isolation will lead, necessarily, to a macroscopic change in habit/habitus accessible to human vision and digital imagery. I need to flesh out some thoughts on this, and search for publications on this idea. I will work on a separate post or a journal entry on this issue and then invite comment.
You can still get Research Grade observations of species outside their normal range, if the computer vision suggestions are to genus, for example, and the species is confirmed by someone who knows what they are doing. But the bar should be a bit higher for such observations. What you don’t want are lots of dubious observations at species level just because someone unthinkingly accepted the automatic suggestions.