To be fair it is certainly nowhere near the scale that you see on iNat, but you do get the same thing for herbarium voucher datasets too. For those who are unaware, within biodiversity databases there is a Darwin Core field for captive/cultivated records called degreeOfEstablishment. This is where you’re meant to fill in your cultivated value, and then in eg the Atlas of Living Australia (ALA), there is a data profile that automatically filters out these records from all default searches and maps, just like iNat does for Casual records. But of course this only works if the herbarium staff/volunteers digitising cultivated records actually fill in the correct Darwin Core field! Unfortunately this is not the case, and there are myriad other fields where the word/value ‘cultivated’ gets added instead, and so all of these records show up on maps exactly how unmarked cultivated iNat records do.
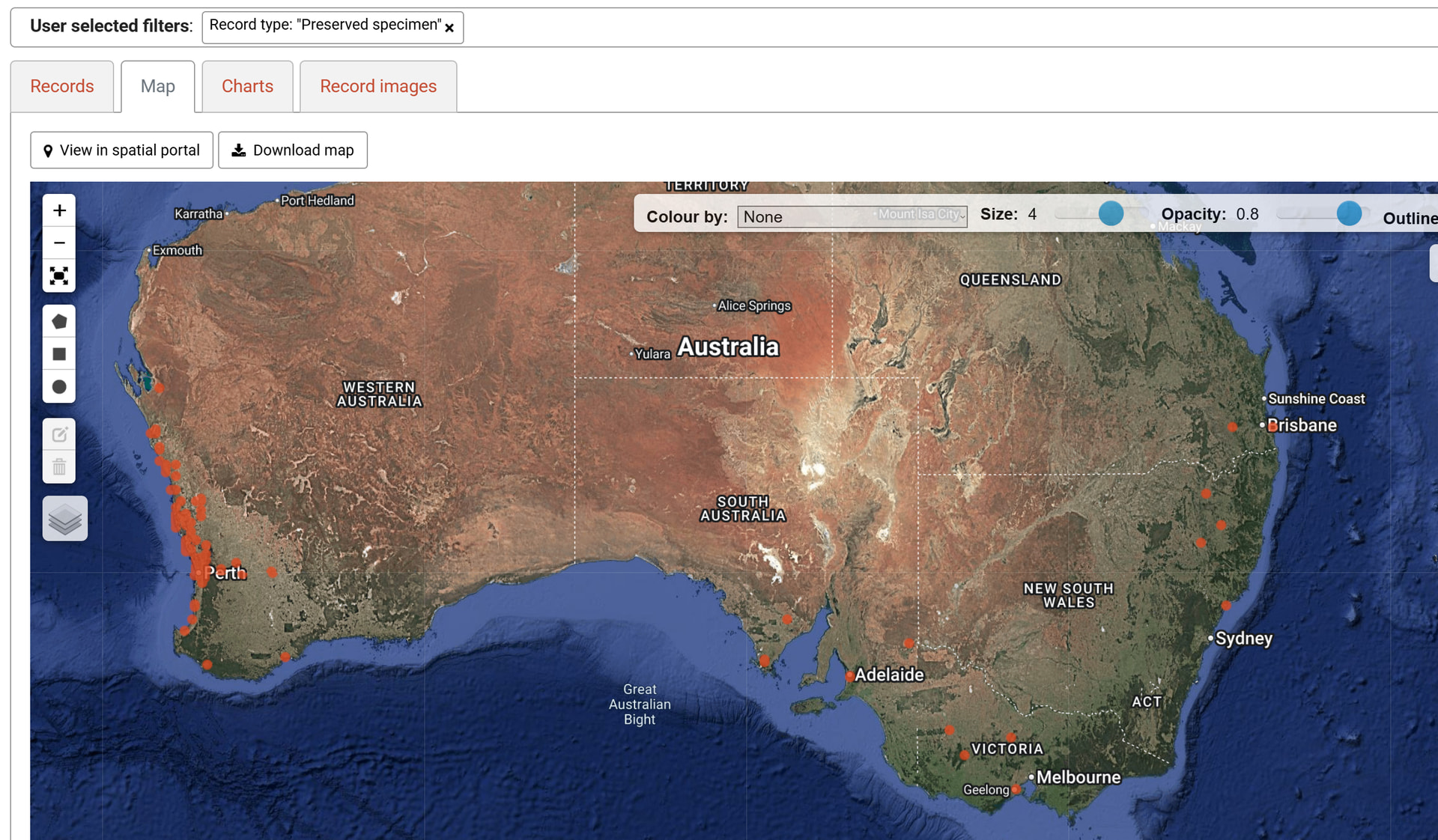
The following map from the ALA shows herbarium vouchers of the plant species Chamelaucium uncinatum, which occurs naturally only in Western Australia.
All of those records (except two naturalised plants) in the eastern half of the country are ‘unmarked’/incorrectly marked cultivated specimens. Some of them do not even explicitly mention the word ‘cultivated’ at all, simply stating the collection was made from a plant in a nursery or botanic gardens. Others do mention the word ‘cultivated’, but in the completely wrong field. For example, one record has filled out the ‘Locality’ field with the comment:
Cultivated by P. & A. Vaughn at Mt Cassel Plant Nursery, Pomonal.
Another one simply states, in the ‘Occurrence remarks’ field:
Large wide spreading shrub. Cultivated.
These are the equivalent of me uploading a cultivated plant to iNat and, instead of ticking not wild, just typing ‘cultivated’ into the location notes or the description.
Broadly, I am yet to find a single data issue, error, bias, etc that isn’t present in both iNat records and herbarium/museum records (again, the scale/magnitude is often quite different of course, but the point stands that these are all biodiversity data issues broadly, and not unique to a certain platform or data stream). Every data quality issue that iNat sceptics/critics ever mention has existed in collections data for decades or centuries before iNat was even conceived.