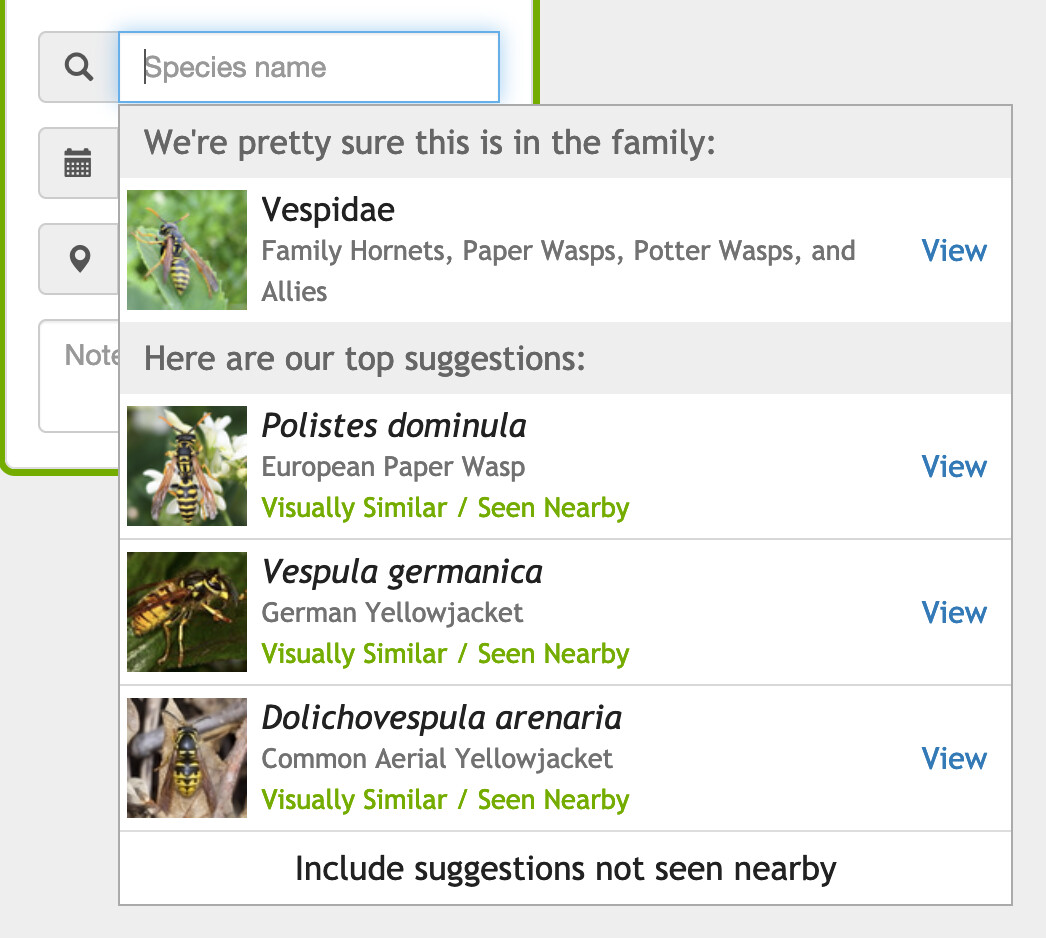
Hi all - we just released a minor change today on the web to remove non-nearby suggestions from the computer vision suggestions by default. We released something similar on Android a week or two ago and a similar change on iOS is coming soon.
We hope will reduce the frequencies of people choosing suggestions that don’t occur nearby and are thus likely wrong. But this is a minor change and doesn’t really get at the heart of whats driving these suggestions so you still may see weird things like common ancestor suggestions (ie “we’re pretty sure its in this genus”) that aren’t seen nearby or may not be optimally calculated. We realize we’re probably due to revisit our whole approach to how we present suggestions (which is coming up on being 4 years old!) - ie the common ancestor and 10 suggestions and how we combine distribution (‘seen nearby’) with the computer vision probabilities (‘seen nearby’). We’ve started some experiments to help guide this work over the coming months, and please bear with us.
But let me explain how this change works with a very simple example using the clade of Giant Southern Pill Millipedes. This order has 5 families with very distinct geographic distributions
But the computer vision model that’s in production right now only includes two taxa in this clade (ie the only possible ‘visually similar’ suggestions). They are Family Zephroniidae and the principle genus in the Family Sphaerotheriidae (green circles below). Note: if we could snap our fingers and have a new model trained up on the current database today it would also include Arthrosphaeridae and the only genus in the Procyliosomatidae (Procyliosoma) - which points to a parallel solution to these issues which is to continue growing the training dataset!
In any case I hope you can see that this set up where we have several geographically disjunct choices that look similar but only a few of them available as choices in the model is ripe for the kind of issues discussed in this thread where non-nearby taxa are continually being suggested by the computer vision algorithm and clicked on. In fact this is what we’re seeing with identifications of Zephroniidae and Sphaerotherium being suggested far outside their ranges in places like southern India etc.
For example, this observation in South Africa was ID’d as the Southeast Asian family Zephroniidae as a result of non-nearby computer vision suggestions.
But with the new change you’ll see that the suggestions now exclude such non-nearby taxa by default. The remaining pill millipede suggestion, the Visually Similar / Seen Nearby Genus Sphaerotherium is in fact the correct choice:
If you click on the new ‘Include suggestions not nearby’ toggle, you’ll now see these non-nearby suggestions as before, including the suggestion of Zephroniidae which led to this mis-ID
Similarly,
this observation from Sri Lanka is now properly ID’d as Arthrosphaera.
But it has an early ID resulting from a computer vision suggestion of the non-nearby Zephroniidae. Again with this change Zephroniidae isn’t suggested even though the correct ID Arthrosphaeridae/Arthrosphaera isn’t suggested because its not available as a suggestion in the current model:
Again if you click on “Include suggestions not seen nearby” you’ll see these non-nearby suggestions of Sphaerotherium and Zephroniidae as before:
Even though hiding these non-nearby suggestions by default was a very easy fix to make we were hesitant to do it because we suspect these changes may lead people astray when they’re in settings where the distributions don’t help a lot with identifications such as gardens. For example, if someone is looking at a garden plant that is commonly observed enough globally to be a suggestion in the computer vision model but isn’t represented by nearby observations (maybe its rarely planted in that part of the world) we are now hiding the correct visually similar suggestion by default. The user will have to know to click on “Include suggestions not seen nearby” to reveal it. We expect that in these use cases the user might click on an incorrect visually similar/seen nearby native plant instead of the correct visually similar garden plant. So hopefully we aren’t just replacing one set of mis-identifications with another.
As mentioned above though, we suspect this will be the the last tweak to our existing setup before a more major revamp to how we go about mashing up distribution data and computer vision suggestions and rolling probabilities up and down the tree to come up with a suggestion or set of suggestions. So please let us know if you think this minor tweak is an improvement to the status quo or not. And stand by for hopefully deeper tweaks to how iNat makes suggestions in the coming months.