The first of these statements may simply be a result of the second.
1 Like
This clarification, while helpful, is not directly relevant to the core of the issue that cotinis describes, where species-level IDs are being offered by CV when experts in those taxa say it shouldn’t.
A fix for this needs to come at the software level, because with the rise in observation numbers and lack of identifer bandwidth in many of the problem taxa suffering from this issue, it is unreasonable to expect identifiers to stay on top of and police IDs for all observations with overly specific CV suggestions.
3 Likes
Unfortunately, I see little evidence of change, planned changes, and recognition of many of these various CV issues from staff. While I could write one big comment summarizing many issues or just my thoughts. It feels I have already done that and I’m not sure there is much of a point anymore. Multiple threads have been made regarding various but largely connected issues with the CV. But most with few if any engagements from staff, especially who work on / develop the CV.
What I can say is, i’m exhausted from dealing with the CVs problems with no staff help, support, or official routes to deal with certain issues. One shouldn’t need to spend over 20-30 hours cleaning a single taxon because the CV was allowed to misidentify that taxon for years creating a pile of 3000+ observations, majority incorrect. As time goes on, certain feedback loops will grow ever larger and unmanageable by a single person, unless that person spends a substantial amount of time and effort, almost like a 9-5 job. Even so, how long would it take to correct 40k observations?
There are real issues brought up here and in other CV problem posts. Almost none have been addressed.
One noteworthy post is here. https://forum.inaturalist.org/t/cv-suggestions-have-gotten-much-much-worse-at-san-jacinto-mountain/68136/15?u=zoology123
But it seems this is a bug, rather than how the CV intentionally is set up.
5 Likes
On the web version of iNat, the suggestions always[1] start with a “We’re pretty sure this is in the genus: [genus]. Here are our top suggestions: [list of species].” The “pretty sure” option is always at the genus level or higher, even if the CV only suggests one species, even if the genus only has one species in it.
The (old) Android app works the same way.
The new app (iNaturalist Next, now default on iOS) does not work this way, unless it has changed in the last few months. It can put a species as the top suggestion, for reasons explained here and here by @tiwane. The rest of that thread (and this thread we are in now) explain why this is a problem and a step backward.
edit: sorry, I missed where you had already mentioned this
unless the CV really doesn’t know what it’s looking at, and isn’t “pretty sure” of even a high-level taxon ↩︎
2 Likes
Yes, I noted this at the bottom of my post. But people selecting the wrong species suggestion – or a species-level ID when it is not justified – did not start with the new app, nor is it unique to app users. They often do so even when they are provided with a top broader suggestion that is correct.
I am aware of what the problem is. But the fact that the taxa the model is trained on and the taxa that it is able to suggest are not identical is highly relevant to understanding the causes of wrong IDs. The CV no longer recognizing many members of a genus once it has learned a species within it (a problem that also comes up regularly in these CV threads) requires a different solution than if the CV correctly recognized the genus but was merely no longer able to suggest it.
Just my 2-cents.
I think an incremental change that would help reduce misidentifications is to force the first identification of an observation to genus when the user selects a species.
When the user submits the observation with a species ID, let the user know what will happen and have the code look up the genus for the species and replace the species ID with a genus ID.
If the user chose anything higher than species, just use that instead.
If the user goes ahead and selects a species ID after they submitted their observations, then that’s on them and other identifiers will see that the species ID is intentional.
Having to ID your own observations twice initially is a small price to pay for better data.
2 Likes
The only way I could be onboard with this is if it applies only to choosing a CV suggestion, not to typing in the name.
4 Likes
For users in Standard Mode in the new app, they do get one main choice. It’s often species, but if the model is not confident at species it will suggest a parent taxon.
Here are all observations made via the new app, of any data quality, by accounts less than 1 week old, so I think it’s unlikely they’re in Advanced mode. If I restrict results to an area I know, like California, I think the results are pretty good. For example, the app wouldn’t go to species here, here, or here, from what I can tell. Certainly not perfect, but I think it does a good job in many cases.
I agree that having the suggestions be more conservative would be an improvement. I’m not sure how difficult that would be, but it’s a suggestion I’ve made to our leadership multiple times.
It seems like a some folks here are taking on a huge burden alone that I think would be a big burden even if/when the CV improves. Thank you for all the work and dedication, it’s making a big difference. However, I’m wondering if it’s possible to make ID resources more available and cultivate a group that can work on a taxon and/or area, similar to what @upupa-epops and others have done for syrphids in North America? I’d be happy to put in some work to help clean up chironomids or funnel-weavers or anything else if there were some easily accessible resources and some clear guidance, and I’m sure others would as well.
I don’t say this to diminish the issues that CV can cause, but to look at the problem from a community angle as well. Data quality issues will, I believe, always require both software and community solutions.
4 Likes
Does the leadership provide any reason(s) for why they do not want to address this?
2 Likes
Good point, but I would say the dissection/sexual organ examination as a basis for species descriptions in groups such as Phyllophaga, is because that is how the reproductive isolation happens. Reproductive isolation is what defines (mostly) biological species.
I’ve looked at a good number of keys for insects, especially beetles, in my area, and most use external characters, though often microscopic. The dissection approach is used when the taxonomist is aware there are clusters of species with similar appearance. Some Phyllophaga do have distinctive habitus, but most do not, so the simplest approach is to dissect the males, put the adeagus, etc. under a microscope, and describe that way. In general, when you see a group where reproductive characters are the basis of a key, it is because habitus is not useful.
There’s an additional problem in many beetle groups, of polymorphisms, often involving mimicry groups. Sometimes closely-related species have multiple strongly-marked forms, but these do not correspond to biological species–the distinctive forms appear across species. I believe this is common in some groups of Meloidae and Lycidae. Some of the “velvet ants” (Mutillidae) have mimicry complexes across several genera. All of those groups can be very difficult to sort out from photographs.
(A couple of minor edits to wording.)
1 Like
Great points. The problem is not just the cv. This can happen with people identifying things over-specifically and then others following their lead. The snowball just builds much more slowly when people are not aided by cv suggestions. I feel the cv just needs higher guardrails for many groups. Those guardrails need to be put in place by human judgment.
1 Like
I feel like the instructions in situations like this can often be something relatively simple like “identification is obvious in the eastern part of the range but impossible in the western part of the range”, which can easily be included in an ID comment on every observation. Often the exact geographic limits of identifiability will be a bit ambiguous, maybe some other nuances in some cases (e.g. most midges are impossible, while a handful are possible but very difficult). But it’s less interesting ID work than situations involving multiple challenging-but-possible species, which are more engaging for identifiers and can be more or less “sorted out” once effort was applied rather than the feedback loops we get here. Not to say that having more ID info out there and more people helping wouldn’t be useful.
2 Likes
Agreed, I think there’s often a conflation of “evidence for speciation” and “diagnostic characters”. If I say two beetle species can only be diagnosed by looking at the shape of the aedeagus, that doesn’t mean the basis for splitting the species was solely aedeagus shape. Cryptic species are split based on a combination of genetics, anatomy, life history, phenology, behavior, etc. Once it’s been determined that there are multiple species involved based on all this data, diagnostic features can be secondarily discovered by comparing long series of specimens that have already been identified to species. This is where the little “bluntness of spines” or “shape of aedeagus” differences come from. Too often I hear people scoff that if two species are most easily diagnosed by one minute feature that they shouldn’t be different species. But that confuses the diagnostic feature with the evidence for speciation. No one looked at three beetles’ aedeagi and said “these are different, so I’m naming them different species”- that’s absurd. They worked out that multiple species were involved based on a combination of many forms of evidence, and then came up with the easiest way to separate them.
3 Likes
The trade-off here is that lots species, like ones in monotypic genera on ones in genera that contain extremely distinctive species, would be placed at genus when the species ID is obvious. Would it take more work to manually ID the influx of those down to species, or to manually push the cryptic species back to genus? I don’t know the answer to that, but every attempt to make the CV more conservative to prevent correction work will inevitably lead to the need for extra work elsewhere to get more obvious things down to species. Unless we can tell the CV to specifically treat different taxa differently based on ease of ID, but that’s the one thing that doesn’t seem possible to do.
2 Likes
I think the best solution to these situations is probably some way for the CV to extrapolate from ratios of species-level vs. higher-level observations in a taxon around a particular location, like this:
Let’s say a particular insect species A is only identifiable at a particular life stage or if a particular angle is photographed. There are enough observations with those criteria to get it into the CV. There is a similar but less common species B in the same genus with overlapping features such that it is expected to be in the area, but there are few if any identifiable observations of it. Because of the overlapping features, there will be many observations which are presumably species A but must remain unidentified.
As I understand it, the CV is only trained on leaves. As a result, if these are the only 2 species in the genus, the CV will only learn about the existence of species A. Under the current circumstances, it is unlikely that it will ever learn about species B or have any hint of its existence. But if you looked at observations of the genus it will be clear from the ratios of observations that there’s something else going on.
For the case in point, there are 14,500 Sinea observations in total. There are 9 species with observations, but only two of those have enough observations to be included in the CV. Together those two species only have 920 research grade observations (6% of total observations of the genus, 14% of observations identified to species level). From the knowledge that the CV is given, it’s reasonable for it to assume that every observation must be one of those two species, instead of e.g. S. incognita, since it doesn’t know the others exist. But a human can look at the situation and see there’s something more going on because of the remaining 94% of observations and the other species with barely any observations. One variable that would help here is knowing how many of those 94% have a community ID at genus level (i.e. have been confirmed by an identifier to genus rather than just being left unidentified), but that’s not possible to search currently (1, 2)
In this case we’re fortunate that there are two species in the system, as they should balance each other out. It could be worse if only one had sufficient observations.
This result is confusing to me. Both species are all around in the geomodel (1, 2) and they look basically identical. What would be biasing it towards spinipes? The recent geomodel update didn’t change anything either since I’m still getting a similar result when IDing that obs:
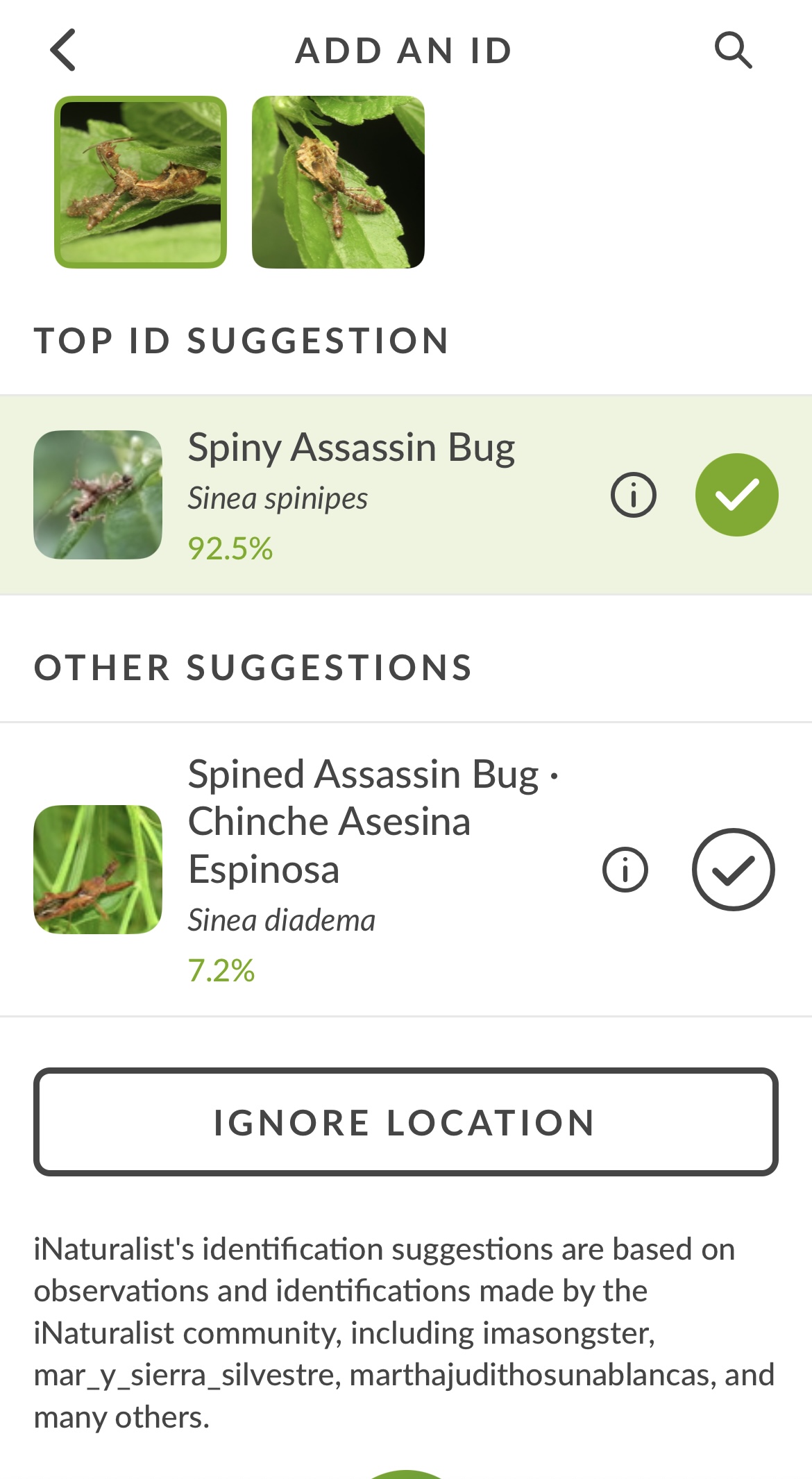

2 Likes
Okay my bad I missed this detail which would explain it… If this is the issue then it should be solvable by going through all the S. spinipes nymph observations and identifying them back to genus (or diadema if there are cases where that’s possible). Tedious but not unsolvable. Like I said there shouldn’t be as big of an issue if there are two similar species because they should balance each other out, or if neither of them are identifiable.
I should make sure to reread a thread closer if I’m replying to it again weeks later, I feel like it got distracted into an adjacent but different direction.
No worries about the delay, etc. This problem is hard to understand until you’ve seen it. Though not “unsolvable”, the problem will repeat itself, even after all ID’s are moved back to genus. Once one person gives another unjustified species-level ID, the cv system picks up on that and offers it as a suggestion. The overall appearance looks good, so people agree. Then the whole taxon fills up with unjustified ID’s again. The issue does not stay fixed–people have to keep fighting the interaction of the cv model with people’s incomplete understanding.
I’ve seen this issue with the name leading people to over-specify the idea in other genera. In the big showy ground beetles, Pasimachus (“Warrior Beetles”), one species, Pasimachus elongatus, is called “Blue-bordered Pedunculate Ground Beetle” here on iNaturalist. It seems people see that common name, note that their beetle has a blue border, and assign it to that species. Problem is, many of the species in that genus have a prominent blue border. P. elongatus itself has a limited range, and their were many out-of-range records based on these ID’s. I corrected a bunch back to genus based on range, but the truth is, members of this genus are quite similar, and most cannot be identified to species without the beetle in hand and consulting keys. I feel the cv should not be making any species-level suggestions in such groups.
1 Like
Referring to ID of a Sinea nymph from Connecticut you referenced. I left detailed comments there. The commenter affirming Sinea diadema for that nymph referred to a worldwide key (Weirauch et al., 2014) that does not go beyond tribe level. The other key referenced (Britton et al., 1923) is meant to apply only to adults, though it does not say so at that point. More recent keys for Sinea apply to adults only. I think that is pretty standard for Heteroptera.
There is a key specifically for Sinea nymphs of the Midwest, and it might be applicable here:
McPherson et al. 2006. Identification of Nymphs of Midwestern Species and Instars of Sinea… Annals of the Entomological Society of America: 99 (5): 755–767
https://doi.org/10.1603/0013-8746(2006)99[755:IONOMS]2.0.CO;2
This key is very involved, and requires microscopic examination of a number of characters. It seems one needs to know the instar (life stage) of the nymph in question as well.
2 Likes
I must admit, I am guilty of this specific thing (IDing all spiny Sinea nymphs as spinipes)! Thanks for bringing this specific issue to light, as well as the broader issue of overspecific IDs driven by the CV
2 Likes
Following up on that likely questionable ID of the Sinea nymph from Connecticut, it occurs to me that the presence of two inapplicable references is an indicator of an AI-assisted comment. I am not totally against AI, but this sort of thing is typical of what I see now as a college instructor. Students seem to have unlimited faith in AI’s ability to generate correct responses to the most complicated and/or subtle questions. The references there are not hallucinated, at least, but they do not support the statements made. This sort of thing makes me deeply skeptical of plans to use AI-generated content to assist with ID’s on iNaturalist–there’s a thread on that somewhere here in the forum.
5 Likes