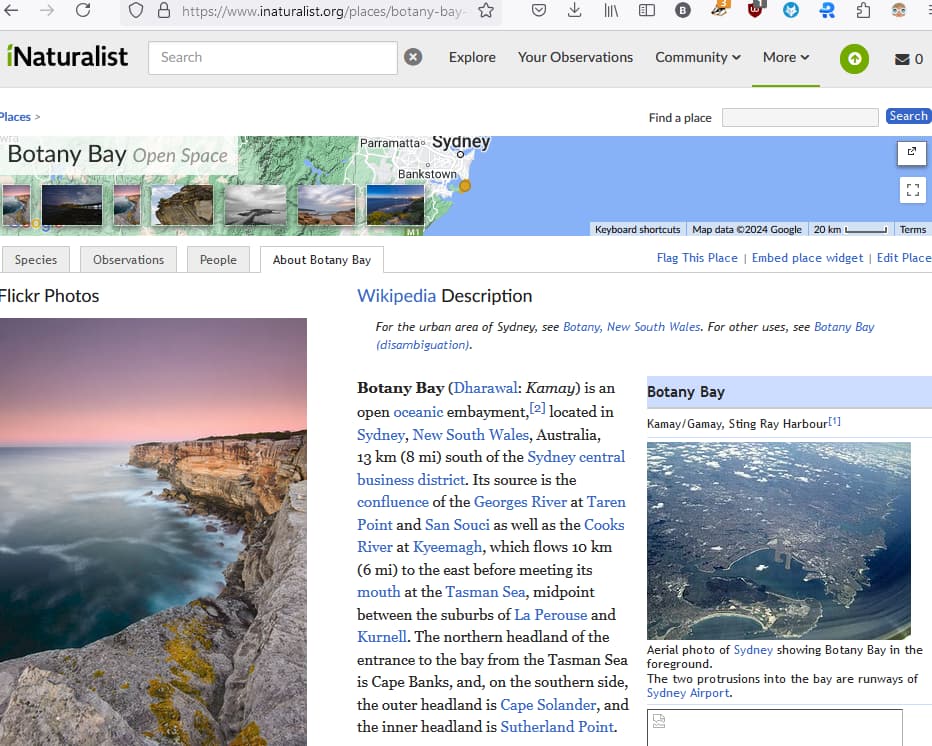
[edit:] Ultimately, the problem with the images seems to be how the Wikipedia source is imported. I don’t know how iNat does this, but I think it might involve fixing some of iNat’s wikipedia import code for places.
Opening the iNat place page in Developer Tools and clicking the “About Place” tab allows me to debug further …
See all of the “Mixed Block” below in the Network pane?
This is because the src attribute for each broken image has http://upload.wikimedia.org which does not match https: for the iNat page. Because the content is insecure, the browser doesn’t allow it, as it is untrusted. If we right-click the broken image and select “Inspect” to open it in the Inspector, we can find the offending URL and edit it locally (note: only has an effect in the local browser session, not the upstream websites)
With the URL corrected like this, the image now embeds successfully on the iNat site:
On the other hand, the srcset attribute has //upload.wikimedia.org (note, neither http: nor https: is present in the URL). This srcset is used to provide responsive images, which explains why they show correctly on mobile, as the responsive image resizing comes into effect for those platforms, and any URL that starts // uses the same protocol as the web page that includes that asset (so, https: when included in an https: page).
I originally thought this could be fixed by editing the Wikipedia source, but that just has:
{{Infobox body of water
| name = Botany Bay
| native_name =
| native_name_lang =
| other_name = Kamay/Gamay, Sting Ray Harbour<ref>{{Cite web|url=https://www.nma.gov.au/exhibitions/endeavour-voyage/kamay-botany-bay/settling-on-a-name|title= Settling on a name|website=[[National Museum of Australia]]|accessdate=26 March 2023}}</ref>
<!-- Images -->
| image = Sydney from Botany Bay looking north (aerial).jpg
| alt =
| caption = Aerial photo of [[Sydney]] showing Botany Bay in the foreground. <br/>
The two protrusions into the bay are runways of [[Sydney Airport]].
…
The Infobox macro should be emitting the correct HTML, so I don’t know how iNat’s import gets it wrong. If I simply use curl with the URL for the page, I see links to images like:
<img src="//upload.wikimedia.org/wikipedia/commons/thumb/e/ec/Sydney_from_Botany_Bay_looking_north_%28aerial%29.jpg/264px-Sydney_from_Botany_Bay_looking_north_%28aerial%29.jpg"
decoding="async" width="264" height="198" class="mw-file-element" srcset="//upload.wikimedia.org/wikipedia/commons/thumb/e/ec/Sydney_from_Botany_Bay_looking_north_%28aerial%29.jpg/396px-Sydney_from_Botany_Bay_looking_north_%28aerial%29.jpg 1.5x,
//upload.wikimedia.org/wikipedia/commons/thumb/e/ec/Sydney_from_Botany_Bay_looking_north_%28aerial%29.jpg/528px-Sydney_from_Botany_Bay_looking_north_%28aerial%29.jpg 2x"
data-file-width="1600" data-file-height="1200" />
That looks correct to me! I wonder if iNat uses a Wikipedia API endpoint that outputs the content in a way that breaks these links?