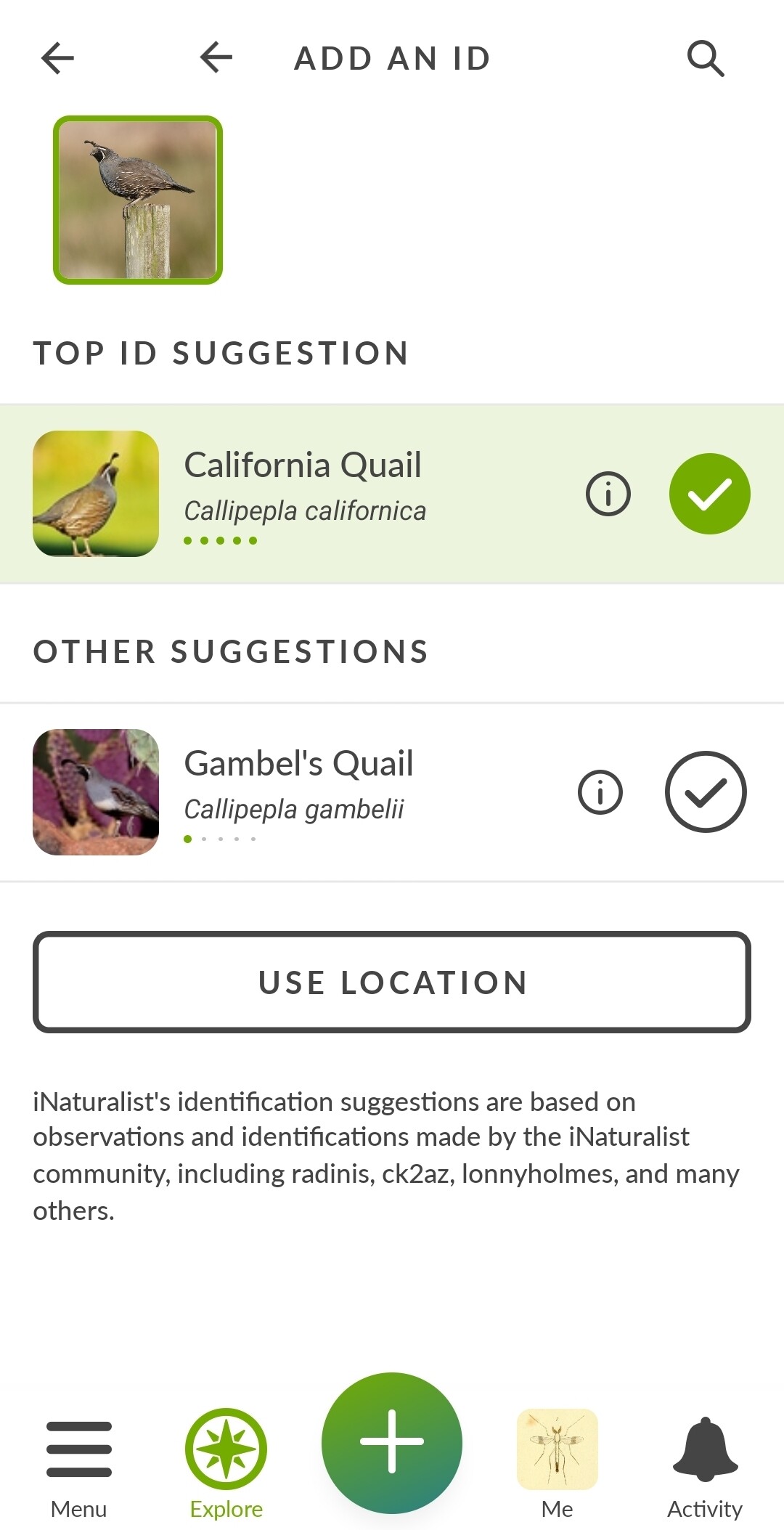
Not sure if this should be described as a bug or a feature request… but it always seems strange to me that if not “Pretty sure of” something, the CV will nevertheless suggest something as specific as a species level ID.
E.g.
Here it isn’t pretty sure of anything…yet the top two suggestions are species level and both incorrect.

Here it is pretty sure its something, and thats only a superfamily, but thats correct.

Wouldn’t it be better if it always showed the lowest common denominator of the top suggestions? Even if that ends up being a “Pretty sure its a Fly!” … if it comes to it, rather than autosuggest something species level but uncertain?
As with human identifiers, and the suggested “Identification etiquette”, ideally, I think the top AI autosuggest should represent the level it has an actual degree of certainty about. My hunch being that users, like myself at times, will just select the option at the top of the list if they have no idea, to keep things quick.
Species level IDs with very little certainty increase the chance of incorrect RG observations slipping through the net, creating the kind of feedback loops we see noted in the CV clean-up wiki.
It’s also more work for identifiers if their IDs involve a conflicting branch, than it is to advance a coarser ID to a lower rank.
Alternatively…
I think I noticed that in the app, it actually states " we are not certain of anything" or something along those lines in this instance?.. I think it would be good to at least have this kind of wording on the website as well as the app, if the above is not possible / desired.